勾引 av VR端3D扮装演出AI发布!南洋理工SOLAMI本事陈诉,唱跳齐能陪你玩

裁剪:LRST勾引 av
【新智元导读】SOLAMI是一个革命的VR端3D扮装演出AI系统,用户可以通过语音和肢体言语与造谣扮装进行千里浸式互动。该系统应用先进的冒昧视觉-言语-行动模子,连兼并成的数据集,提供更天然勾引 av的换取体验,很是了传统的文本和语音交互。
宇宙上第一个VR端 3D版的扮装演出AI就在刚刚出身了!
AI扮装演出类游戏(如C.AI、Talkie)从发布以来,一直齐是东谈主们最心爱的AI居品之一。天然广受接待,但不少用户提议,期待和这些扮装在VR中有更进一步的换取。
近日,来自南洋理工大学的络续团队在VR中完了了第一个3D版扮装演出AI系统SOLAMI,并公开其详备的本事陈诉。没错,这意味着和各式扮装在VR中千里浸式聊天仍是是可完了的!

神志主页:https://solami-ai.github.io/
本事陈诉:https://arxiv.org/abs/2412.00174
竣工先容视频:https://www.bilibili.com/video/BV1D6zpYHEyc/
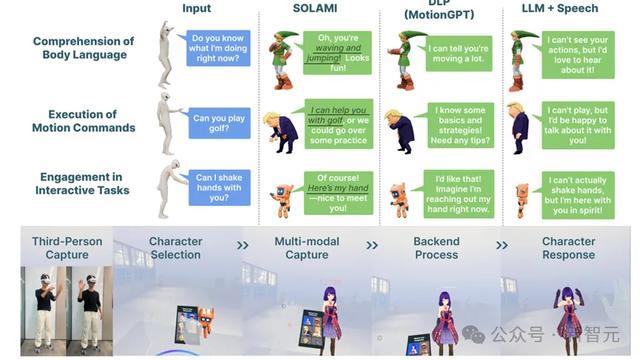
从本事陈诉中咱们可以看到,SOLAMI支持多种扮装,有超等英豪蝙蝠侠,小可人机器东谈主,二次元内助,香蕉猫,宇宙名东谈主特朗普,……

SOLAMI驱动的AI扮装能识别用户的肢体言语,从而去暖和和明白用户.

想让扮装跳个舞?只有说句话,扮装就能听懂作念到.

还可以和扮装玩游戏,比如随着用户节律动起来,大致剪刀石头布.

那么SOLAMI提议的动机是什么?模子是怎样使命的?使用了什么样的数据教练的?
络续配景
大众有莫得想过和一个造谣扮装进行面对面的深度对话?不单是是简便的言语换取,而是能像现实冒昧相似,不雅察对方的面部脸色、天然的肉体言语,甚而是渺小的姿首变化。
心情学络续标明,在冒昧互动中,千里浸进度越高,用户体验就越好。但现在的AI扮装(如Character.ai等) 仍然局限于文本大致语音的交互。这促使咱们念念考:如何构建具有更丰富模态的3D自主扮装呢?
要完了这个谋略勾引 av,主要濒临两个挑战:
1. 3D扮装需要准确不雅察和明白用户行动信息,并基于高下文和扮装设定通过语音、肢体动作和脸色作念出稳妥的回话。这仍是很是了之前的单一任务(动作明白,动作生成,语音驱动肢体等)的规模。
2. 数据稀缺的问题。东谈主和3D扮装进行多模态交互的数据极其稀缺,收罗这类数据需要复杂的配置和弘大本钱。
传统的LLM-Agent框架天然在高端倪任务(如预备和回首)发扬可以,但在明白用户行动和提供实时的肢体言语反馈上存在局限。这是因为用文本四肢子模块之间关系的前言会丢失许多渺小的信息。
风趣的是,机器东谈主规模的络续给了咱们启发:关于低端倪的操作任务,基于LLM构建的端到端量觉-言语-行动 (Vision-Language-Action,VLA)模子发扬更好。数字扮装践诺上即是造谣东谈主形态的机器东谈主,那么构建一个偏向于冒昧互动的VLA模子会不会是一个有后劲的地点?
Social VLA模子

SOLAMI推理图
如图所示,SOLAMI中统共扮装的驱动齐是由一个长入的端到端VLA多模态模子驱动。给定扮装的设定,模子以用户的语音和动作四肢输入,将这两种模态通过Motion Tokenizer和Speech Tokenizer折柳编码为LLM新的词表中的token,LLM基座会自转头输出扮装的语音和动作token,再通过解码器折柳解码为扮装的3D动作和语音,来驱动扮装作念出反应。
与GPT-4o比拟,这个模子多了个用户动作的模态,用于明白用户的肢体言语,生成扮装的动作。
在这里,用户的动作以SMPL-X的3D旋转进行暗意,动作被拆为三个部分:联系于3D扮装的相对位置,肢体动作,和手部动作。折柳经过3个VQVAE进行编码。用户的语音使用RVQ-VAE结构进行编码,使用的SoundStorm进行解码,在解码过程中,只有输入小段扮装的语音四肢prompt,就可以完了声息克隆。
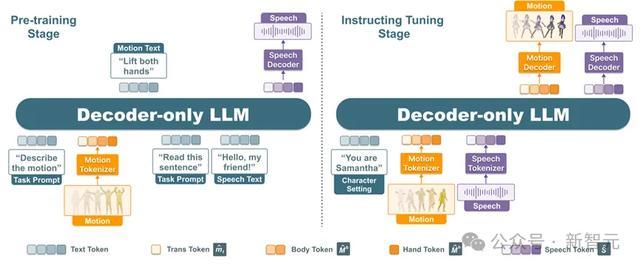
SOLAMI教练过程
模子的教练主要分为两个阶段:多任务预教练和提示微调教练。
多任务预教练阶段主要使用动作-文本、语音-文本关联的数据集进行教练,教练任务包括 text-to-speech, automatic speech recognition,speech-to-speech,motion understanding,motion generation,interactive motion generation六个任务。观念在于让SOLAMI学习动作、语音和文本之间的关联。
提示微调阶段主要教练模子进行多轮多模态对话的才智。使用合成的数据集,模子被要修业习基于扮装设定和用户输入该如何作念出语音和动作的反馈。
数据收罗
用于教练模子的数据是相当稀缺的。毕竟,很少东谈主能和蝙蝠侠面对面说过话。因此,络续东谈主员研讨使用现存不同模态的数据进行合成。
率先,络续东谈主员基于公开的动作-文本数据集构建了一个大规模的带有语义标注的动作库,包含4万多个东谈主体动作,然后使用GPT-4o生成扮装和用户对话的纯文本的台词脚本。
把柄生成的脚本动作,从动作库检索最稳妥的已有动作,把柄检索到的动作修缮好对应的台词。这么生成的笔墨脚本能和合成数据中的动作较好吻合。终末,通过声息克隆合成扮装独到声息。这么,一个低本钱可用的合成数据集得以完了。
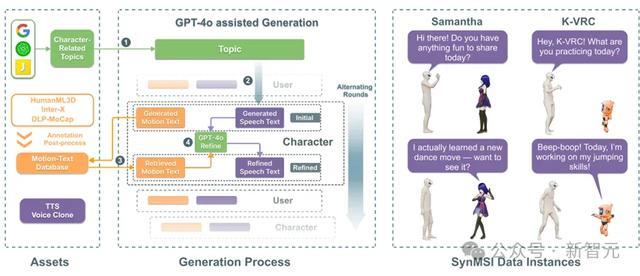
SOLAMI合成数据管线
VR工程完了
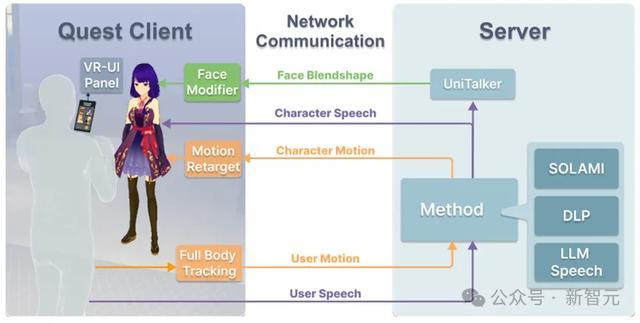
SOLAMI VR工程框架
av收藏夹络续东谈主员基于Oculus Quest 3设备了一个竣工的VR交互系统。
前端支持用户与3D造谣扮装的千里浸式交互,后端由2块H800 GPU提供狡计支持,可以支持多种模子和次序。
在交互时,VR头显会实时捕捉用户的语音和全身动作,发送给后端。后端开动SOLAMI模子,生成扮装的语音、肢体动作和面部脸色反应,发送给前端来驱动扮装。
实验收尾
在本使命中,络续东谈主员但愿探讨两个问题:与纯语音比拟,3D扮装与动作是否会给AI扮装演出带来体验普及?与LLM-Agent结构比拟,端到端的VLA结构是否在交互质地和蔓延上有体验普及?
为此,络续东谈主员遴荐了两种对比次序:LLM+Speech,DLP(MoitonGPT)。前者是纯语音的交互,后者是LLM-Agent结构驱动的数字扮装。为了保证公谈,这些次序的基座模子齐是llama2-7B,并使用vLLM部署进行加快。
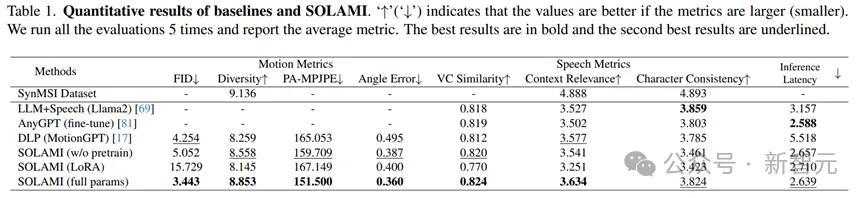
定量实验收尾
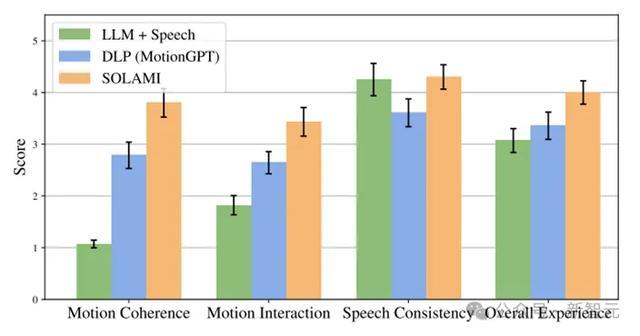
定量实验收尾标明,SOLAMI在动作质地和语音质地上发扬齐优于对比次序,何况有较低的事件蔓延。消融实验也标明,多任务的预教练对模子最终遵守有遑急普及。
实验定性分析与VR使用经过
除了定量熟识外,络续东谈主员还作念了用户实验,通过让用户在VR头显中跟各式扮装互动,何况把柄体验进行打分。可以发现SOLAMI体验赫然好于纯语音次序和LLM-Agent结构次序。风趣的是,天然纯语音次序在对话内容上比LLM-Agent结构次序好,然而总体体验上如故弱于后者,这印证了扮装和肢体言语在AI扮装演出中关于体验的遑急性。
消融实验收尾
总结
络续东谈主员在这篇使命中,提议了一个Social VLA的端到端建模3D数字扮装的本事框架,一种从现存不完备模态的数据合成多模态冒昧互动数据的管线,和一个支持用户和扮装进行千里浸式互动的VR交互系统。
天然,四肢一个新的地点,络续者们指出了一些值得探索的地点,比如输入输出模态的设定、数据征集步地、跨具身问题、黑白时回首问题、手段学习次序等。感酷好的一又友可以参考本事陈诉。



3月21日主力资金净买入4.99万元")
